
On September 27, 2022, Flashpoint’s VulnDB hit the 300,000th entry added to the database. Think about that and .. wow. I started the adventure of collecting vulnerabilities around 1993, back when it was all flat text files, and my hacker group used a FILES.BBS file as an index, pointing to many hundreds of other text files, each with one vulnerability. At the time our collection was impressive; even back then I was brokering vulnerabilities between a few hacking groups to increase the collection.
The wild part? Not all of the vulnerabilities in that collection are in VulnDB. Why, you ask? Trust me, as a Vulnerability Historian (official title at day job!) it bothers me. But I am caught in the middle of a love triangle between collecting all the current vulnerabilities to provide solid vulnerability intelligence as a service, and collecting all historical vulnerabilities which is equally, or more, my passion. Just not enough hours in the day and I have said this for over a decade now; give me 10x the bodies on my team and I will keep them all busy importing vulnerabilities. Yes, it is that bad as far as the number out there, and the number not cataloged in any database, anywhere.
That should be worrying to say the least. Ignore the fact there are that many, focus on the fact that you don’t know about them. Because I am talking about already published vulnerabilities, not the dreaded zero-days. Why burn a vulnerability that may cost hundreds of thousands in development or acquisition fees, when you use public vulnerability with an easily-improved proof of concept to pop a target?
What’s next? Keep collecting of course! Generally speaking, I am still pushing for a bigger team, more developers, more fields, more meta-data, and more ways to integrate that data. Personally? I want two things. First, a team big enough that can I focus exclusively on historical vulnerabilities while the team expands current collections. Second, for us to hit 100,000 vulnerabilities that don’t have an assigned CVE ID. Currently over 97,600 public vulnerabilities missing in both CVE and NVD.
The wild part? Hardly anyone knows just how bad their criminally over-priced taxpayer funded vulnerability intelligence really is. Let that sink in.
The Dirty Secret
First, this is extremely pedantic and I know that! But that is the world vulnerability database nerds live. We have the most pedantic discussions you can imagine, and then some a lot more than that. The Flashpoint blog says that we aggregated 300k vulnerabilities as of that day, and we did… kind of, sort of.
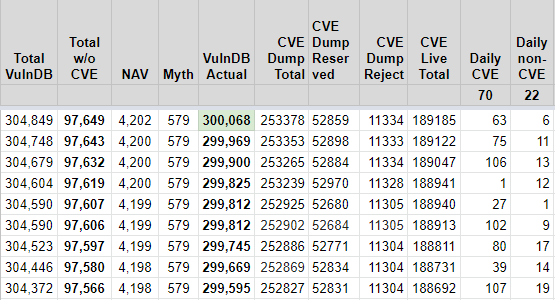
VulnDB aggregated 300k vulnerability disclosures, and that is accurate. But that doesn’t mean it is actually 300k legitimate vulnerabilities. So, will the real 300k stand up? Let me break it down:
- VulnDB ID 300,000 passed many months ago and that was due to some entries being deleted in the old days, and some more being deprecated as duplicates since then.
- The VulnDB portal says 300k, but that isn’t it either. The database has to track some disclosures that are not actual vulnerabilities. Some start out legitimate before subsequent examination proves they aren’t. Some are valid stability bugs, but they don’t cross privilege boundaries and therefore aren’t actual vulnerabilities.
That begs the question, how many legitimate vulnerabilities are there? If you subtract the 4,202 “Not A Vulnerability” (NAV) disclosures, and subtract the 579 “Myth/Fake” disclosures, you have 300,068 total vulnerabilities as of today.
That number is both a milestone and completely arbitrary at the same time. It’s arbitrary, because organizations really don’t care if there’s 300,000 versus 300,001 vulnerabilities at this point. They have a hard enough time patching some fraction of that total and we continue to see data breaches and compromises in scary volumes. Just imagine what these companies would do if they saw how many more vulnerabilities are out there, out of their eyes due to reliance on CVE and NVD.
It’s pretty grim.
Leave a Reply