
[This was originally published on RiskBasedSecurity.com.]
On March 9, 2017, RAND released a report (PDF) titled “Zero Days, Thousands of Nights; The Life and Times of Zero-Day Vulnerabilities and Their Exploits” by Lillian Ablon and Andy Bogart that received a fair amount of press. The RAND press release goes on to describe it as “the first publicly available research to examine vulnerabilities that are still currently unknown to the public“. While the report covers many topics and angles around this discussion, one specific bit that caught our attention was the data put forth around vulnerability rediscovery. From the press release:
Based on the dataset, RAND researchers have determined that zero-day vulnerabilities have an average life expectancy—the time between initial private discovery and public disclosure—of 6.9 years. That long timeline plus low collision rates—the likelihood of two people finding the same vulnerability (approximately 5.7 percent per year)—means the level of protection afforded by disclosing a vulnerability may be modest and that keeping quiet about—or “stockpiling”—vulnerabilities may be a reasonable option for those entities looking to both defend their own systems and potentially exploit vulnerabilities in others’.
Specifically, their analysis suggests that collision rates are rare among researchers, which seems entirely too low even at first glance. Unfortunately, they use a closed data set, making it impossible to validate their findings. This low collision rate analysis caught the eyes of others in the industry as well. Many researchers and others involved in vulnerability aggregation generally have the impression that rediscovery isn’t that rare, but as RAND notes, there isn’t a lot in the way of research on this topic. In 20 years of aggregating vulnerabilities in one form or another, RBS has not specifically looked to track this data point. We track a great deal of metadata about each vulnerability disclosed, but do not currently have a classification for research collisions
RAND is presenting at BlackHat Briefings USA in Las Vegas this year, on the back of public discussion and some solid criticism of their report, we at RBS were also curious about the rediscovery rate. Since the dataset used for the RAND report is not public and anecdotal ‘data’ does not cut it, we decided to create a new public dataset based on VulnDB to help us better evaluate their report and findings; more on that later.
First, let us examine how RAND describes their own dataset:
In an effort to address the question, RAND obtained rare access to a dataset of information about zero-day software vulnerabilities and exploits. It is a rich dataset, as some of these exploits have been found by others, but others have not. The dataset spans 14 years (2002–2016) and contains information about more than 200 zero-day exploits and the vulnerabilities they take advantage of, over half of which are publicly unknown. The data we received had a final count of 207 exploits, after approximately 20–30 were removed due to operational sensitivity. [..] This dataset includes exploits for 64 vendors, with a range of 1 to 55 exploits per vendor. Microsoft (n = 55), Linux (n = 39), Apple (n = 14), and SUN/Oracle (n = 11) each had the most number of exploits, while the majority of the other vendors each had one or two exploits. These include well-known vendors such as Mozilla, LinkSys, Google, Citrix, AOL, Ethereal, Adobe, Alt-N Technologies, CryptoCat, and RealPlayer/RealServer, as well as some lesser-known vendors.
For ease, there are several key points pulled from this statement:
- 207 “zero-day” exploits, with half of them not publicly disclosed, we interpret this to mean that half of the zero-day exploits are now publicly known
- 14 years worth of data (2002-2016)
- 20-30 exploits “removed” for operational sensitivity
- 64 different vendors had exploits included
When reviewing the key points it becomes very interesting, as in the world of exploits it suggests the data came from an exploit broker or, more likely, a government-run or funded shop that produces a considerable number of high-quality exploits themselves. However, later when talking about the limitations of the research, they write:
“Ideally, we would want similar data on Red (i.e., adversaries of Blue, or other private-use groups), to examine the overlap between Blue and Red, but we could not obtain that data.”
This quote suggests that the data was captured by a Blue team, which used a certain level of technology that allowed them to identify a high number of zero-day exploits used in the wild, against their network.
Using the dataset described above, RAND analyzed it and produced the following results:
Finding #4: For a given stockpile of zero-day vulnerabilities, after a year, approximately 5.7 percent have been discovered by an outside entity. [..] In our analysis, collision rates changed significantly depending on the interval time used (from 40 percent to less than 1 percent), and so the timing of “flushing” a stockpile of dead vulnerabilities matters. We found a median value of 5.76 percent overlap (6.79 percent standard deviation) given a 365-day time interval, and a median value of 0.87 percent overlap (5.3 percent standard deviation) given a 90-day time interval. A 14-year interval (i.e., all of our data in one time interval) yielded a 40 percent overlap. With the exception of the 14-year interval, our data show a relatively low collision rate. This may be because those in the private exploitation space are looking for different vulnerabilities from those hunting for vulnerabilities to share as public knowledge, as well as using different techniques to find the vulnerabilities (e.g., vulnerabilities found via fuzzing, or automatic software testing, are often different than those found via manual analysis).
There is a lot going on in this single finding, and it is worth dissecting further. When looking at the overlap value as compared to the interval time it is certainly interesting and a great data point, but without knowing anything more about the dataset used, it becomes kind of pointless.
Here are a few points to consider:
- The overlap varies from < 1% to over 40% depending on the interval. Based on that wide range alone it makes one question the credibility of this claim.
- On the surface it may sound logical that as more time passes, more vulnerability collisions occur. However, consider that in the span of 14 years many versions of products assumed to be in the dataset (e.g. Windows, Linux, Office, Flash Player, etc.)included in the analysis may have become obsolete.
- To properly perform this analysis, the dataset would require having the vulnerability discovery and exploit creation date for the first and second researcher.
- Based on RAND’s description, they would have the date for the first researcher, but likely not the second. If they worked with vendors to determine the collision rate, they would have the second researcher’s date for when it was reported to a vendor, or when it was discovered internally by the vendor, but most likely not have the discovery and exploit creation date for most of the vulnerabilities.
RAND makes one other observation about the low collision rate they observed, saying this “may be because those in the private exploitation space are looking for different vulnerabilities from those hunting for vulnerabilities to share as public knowledge“.
Finding #5: Once an exploitable vulnerability has been found, time to develop a fully functioning exploit is relatively fast, with a median time of 22 days
On the surface, this claim does not appear to have merit. Due to a wide range of factors during exploit development, it can be completed very quickly or take a significant amount of time. However, based on our past experience, that range is anywhere from half an hour, to days, or even several weeks or longer to ensure a reliably working exploit . With such a small dataset, and without additional meta-data, such a claim while maybe valid in their analysis, it simply cannot be used as a metric for larger analysis of the issue.
In VulnDB, we have implemented our own standard to track and provide Vulnerability Timelines and Exposure Metrics (VTEM). We believe that it is key to better understand metrics on how vendors respond to vulnerabilities e.g. the average time organizations have to apply available fixes until exploits are published. While one can surmise that the exploits in question are high-end (e.g. overflows, memory corruption, use-after-free), it is simply impossible to determine if 22 days for exploit development is consistent with any other vulnerability rediscovery dataset. In a larger view of vulnerability research, finding a vulnerability may be part of your day job, but they may not require you to write a functioning exploit for it. Just to highlight the sample bias potentially at play: It would be trivial to create a dataset that is twice the size as the one used, which ‘proves’ a median time of a single day for exploit generation after the vulnerability was found. Just come up with a list of 500 cross-site scripting (XSS) vulnerabilities and use that as your dataset. Voila!
Finding #1: [..] In the course of investigating life status for our vulnerabilities, we found that Common Vulnerabilities and Exposure (CVEs) do not always provide complete and accurate information about the severity of vulnerabilities.
This is not a new finding by any stretch, but it does demonstrate that more and more of our industry are realizing the shortcomings of relying on CVE/NVD for vulnerability intelligence. If you want to understand the gap further just check out any of our VulnDB QuickView reports.
To contrast their data, RAND cites the previous research on this topic as:
Literature on collision rate focuses mostly on vulnerabilities reported to vulnerability reward programs or publicly found and reported within a code base. Finifter, Akhawe, and Wagner (2013) found that roughly 2.25–5 percent of all vulnerabilities reported to vulnerability reward programs had been discovered by others. Past RAND rough order-of-magnitude estimates put the probability that a vulnerability is discovered by two parties within a year at approximately 10 percent (Libicki, Ablon, and Webb, 2015). Researchers in 2015 created a heuristic model that found a 9 percent overlap in non-security-tested software and 0.08 percent in more secure software (Moussouris and Siegel, 2015).
Shortly after the RAND paper was published, another paper titled “Taking Stock: Estimating Vulnerability Rediscovery” by Trey Herr, Bruce Schneier, and Christopher Morris was published. Their conclusions are considerably different than RAND’s, and also use a much larger dataset.
From the paper’s description:
This paper presents a new dataset of more than 4,300 vulnerabilities, and estimates vulnerability rediscovery across different vendors and software types. It concludes that rediscovery happens far more often than previously estimated. For our dataset, 15% to 20% of vulnerabilities are discovered independently at least twice within a year. For just the Android sample, 13.9% of vulnerabilities are rediscovered within 60 days, rising to 19% within 90 days, and above 21% within 120 days. Chrome sees a 12.87% rediscovery within 60 days; and the aggregate rate for our entire dataset generally rises over the eight-year span, topping out at 19.6% in 2016. We believe that the actual rate is even higher for certain types of software.
With RAND’s closed dataset, and Herr et al’s dataset created on open data (but not distributed with the paper), RBS thought it would be interesting to offer a dataset focused on Microsoft that is open and available. It was created to show that serious bias can be introduced based on a given data set. We are not stating that this dataset is accurate and any other is not; simply that many factors must be considered when creating vulnerability statistics. Without their datasets published, other researchers cannot validate their paper’s findings or build on their data. While the RBS dataset is being made available, it is a draft / proof-of-concept more than anything. The dataset, titled “PoC Vuln Rediscovery Dataset Using Microsoft Creditee Data“, has additional notes and caveats to illustrate some of the pitfalls when performing this type of research.
The following two charts based on our dataset show the Total Vulnerabilities in Microsoft Advisories and the approximate Percentage of Vulnerabilities Rediscovery by Year:
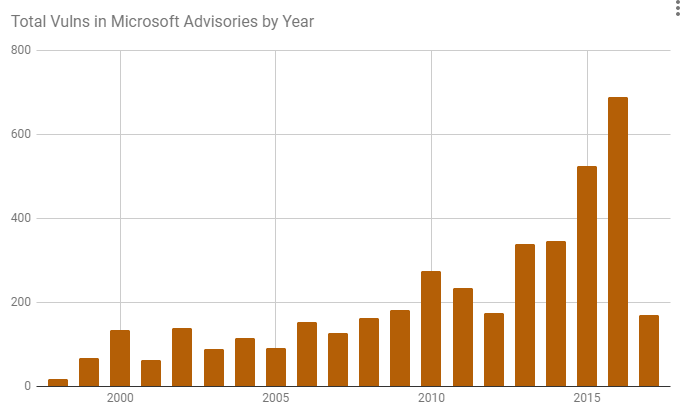
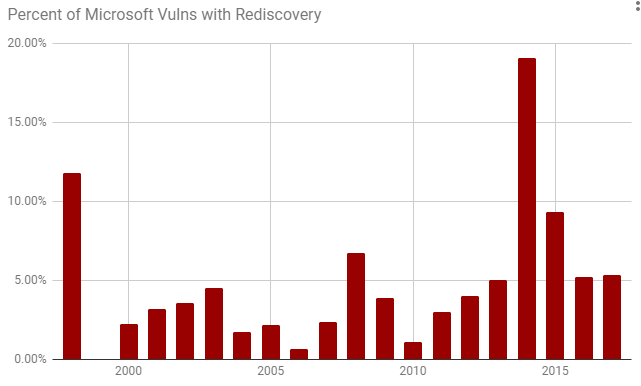
While creating this dataset, we made some observations and came up with questions for the industry to consider:
- Microsoft changes their acknowledgement format from time to time and does not use a consistent format, so this dataset could be enhanced.
- Microsoft does not always credit the person who found a vulnerability. Examples include if it wasn’t reported directly to them or researchers disclosed before Microsoft was ready.
- When there is a collision, Microsoft does not indicate which researcher reported first.
- In 2016, Microsoft changed their format to make it more difficult to determine collisions from the same company. While fairly rare, a company that maintains several research groups (e.g. HP, Qihoo, Tencent) may be the source of a collision.
- Starting in 2016, Microsoft became less precise in acknowledgements, not even listing the collision researchers together.
- We found evidence of “double dipping” in third-party bounty programs, something long suspected but we don’t believe has been proven. (CVE-2014-0270 credits Jose A. Vazquez of Yenteasy working with HP’s Zero Day Initiative and separately as working with VeriSign iDefense Labs).
- There may be additional collisions, but they are hard to determine based on MS and ZDI advisories. For example, CVE-2015-6136 is credited to “Simon Zuckerbraun, working with HP’s Zero Day Initiative” and “An anonymous researcher, working with HP’s Zero Day Initiative”. Of the seven ZDI advisories covering this one CVE, one is attributed to anonymous and the rest to Zuckerbraun suggesting they are distinct reports. Having to evaluate dozens of cases like this to refine a dataset is time-consuming.
- Did either the RAND or Herr et al’s dataset show a big uptick in vulnerability rediscovery in 2014 like our Microsoft dataset does?
- Nine different researchers discovered a single vulnerability in one case (CVE-2014-1799). Did the prior research account for the number of researchers in a single collision?
What is quite clear from each of the datasets is that vulnerability rediscovery is not only prevalent, but – depending on a number of factors – may be considerably more frequent than we imagine. To further illustrate this, consider that on June 28th, HackerOne tweeted out a statistic of their own regarding rediscovery.
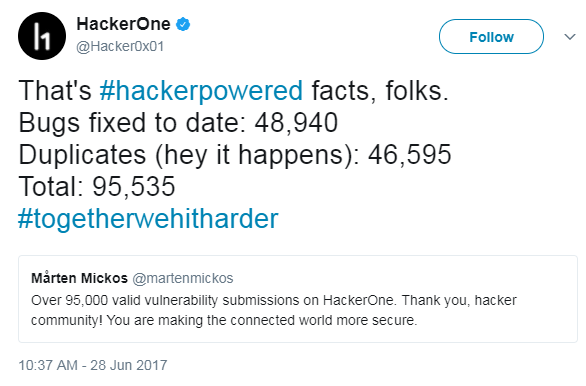
The HackerOne statistics makes it pretty clear (quite concerning actually!) that rediscovery or duplicates, as it is known in the bug bounty world, are extremely prevalent. A higher collision rate with bug bounties programs run by HackerOne or other companies actually make a lot of sense for the most part. The expectation from this data set is most likely lower maturity bugs, which are easier to find such as XSS, SQLi and are also heavily focused on companies websites as well.
We have spent a lot of time researching Bug Bounties over the years, and researchers are definitely motivated by money. Researchers look for bugs when there is money to be made or if there is some very cool technology or fame to be gained. With more and more bounty programs that are encouraging more researchers to look for vulnerabilities, we, therefore, would also expect more eyes looking for the same exact issues and often using the same tools even.
In contrast with the assumed RAND dataset, the expectation is that they are high-end and much more complex vulnerabilities than most bug bounties. These higher-end vulnerabilities typically require more technical skills to find and it, therefore, makes sense to see a lower rediscover rate. We at RBS have been working hard on implementing our Code Maturity metrics into VulnDB. Once completed, we expect to see rediscovery rates are much lower for products with a higher code maturity.
The concept of finding higher severity bugs in more mature products as well as websites also apply to bug bounties. In the “Taking Stock: Estimating Vulnerability Rediscovery” paper they cite data from Bugcrowd, as they found that:
Rediscovery happened least often with their highest severity bugs, 16.9% of the time. For second- and third-tier vulnerabilities (based on a five-tier system), the rediscovery rate jumped to 28.1% and 25.8%, respectively.
Based on RAND’s report and our own impromptu dataset, it is clear that the data you work with can strongly influence the observations and results of your research. As we have long maintained, vulnerability research of this nature is never perfect, largely due to the challenges of maintaining high-quality vulnerability data. With this in mind, such research should definitely move forward! However, it is extremely important to disclaim and caveat the data and resulting findings to make it clear where the original data may be lacking or how a conclusion may be based on incomplete data.
If you are attending Black Hat and are interested in further discussions on this topic, then consider attending a panel moderated by Kim Zetter that plans to dive further into the topic and reports.
Leave a Reply