If I had a nickel for every time Anthropic’s new Project Glasswing / Mythos initiative came up in conversation or I was asked directly about it in the last few days, I would have a shit ton of nickels! Let’s dive into it… first with brief observations about the announcements and available information, other’s opinions, then a broader opinion of my own on where this is all going.

Observations
Project Glasswing is “a new initiative that brings together Amazon Web Services, Anthropic, Apple, Broadcom, Cisco, CrowdStrike, Google, JPMorganChase, the Linux Foundation, Microsoft, NVIDIA, and Palo Alto Networks in an effort to secure the world’s most critical software.”
Just one sentence, but a lot to unpack there! First, all of this is being spearheaded by a so-called AI company rather than any of the others that have a much longer history steeped in vulnerabilities, especially ones exploited in the wild (aka KEV). Second, all organizations associated with enterprise software and a bank, which stands out as odd. Sure, JPMorganChase has software used by both enterprise and consumer, but so do hundreds of other Fortune 500 companies. Last, why in 2026 do we see those major software vendors that have software frequently hit by threat actors finally saying “it’s time to do something”? Is this a confession that they couldn’t do it entirely with their own human staff and must rely on this new-fangled AI software? Is that a tacit confession that they couldn’t do security all along?
| KEV according to VulnDB | 1,341 |
| Amazon Web Services | 2 |
| Anthropic | 1 |
| Apple | 118 |
| Broadcom | 68 |
| Cisco | 155 |
| 129 | |
| Linux Foundation | 68 |
| Microsoft | 778 |
| Palo Alto Networks | 22 |
As always, all vulnerability statistics should come with disclaimers or you should be wary! First, ‘Broadcom’ is difficult to track due to their many acquisitions so this number reflects Symantec (9), AMD (1), and VMware (58). Second, these are fairly accurate but based on title searches in VulnDB which may include an occasional hit for a different product e.g. CVE-2023-49103 “ownCloud graphapi microsoft-graph/tests/GetPhpInfo.php URL Handling Remote Information Disclosure” which I exempted when I noticed. Last, while CrowdStrike has zero directly attributed KEV in their software, they have their share of vulnerabilities and a nasty global incident to consider. Remember, these are just the vulnerabilities that are known to be publicly exploited meaning they lead to real-world harm, often including ransomware, cryptojacking, and/or data loss (exfiltrated or destroyed).
What is Mythos? From the Glasswing article, it says “Claude Mythos2 Preview is a general-purpose, unreleased frontier model that reveals a stark fact: AI models have reached a level of coding capability where they can surpass all but the most skilled humans at finding and exploiting software vulnerabilities.” That’s a bold claim. Sure, this type of software is certainly making big strides very quickly, but this is still the same software that can hallucinate vulnerabilities. So every single claim of a vulnerability must be fact-checked for the near future. Later in this blog, I will cite information that will cast doubt upon these claims.
The Cloud Security Alliance has published a paper on Mythos titled “The “AI Vulnerability Storm”: Building a “Mythosready” Security Program“. The list of authors and contributing authors is mostly full of a “who’s who” in security and the so-called AI landscape, definitely some heavy hitters here. Then add the 73 reviewers (!!) for this 28 page document, that is 2.6 reviewers per page. Seems to me like overkill or stacking as many names on this initiative as possible, especially with only 23 pages of content. I don’t keep up with the latest buzzword trends, but this is the first time I have seen “VulnOps” too. New-fangled term for an old-school idea. Anyway, from the paper, this paragraph stood out to me:
This matters because many of the assumptions underlying our cyber defense programs are being challenged. For example, time to exploitation has been reduced to minutes, we can no longer assume a patch will be ready in time for remediation purposes, incident frequency is likely to increase, the CVE system may not scale, shadow IT will fragment central control as coding agents proliferate to Citizen Coders, employees develop their own infrastructure, and threat intelligence is lagging behind on vulnerability discovery and exploitation.
While I bolded one bit that is laugh-inducing, more than that screams “we don’t work with vulnerabilities” despite many of the authors and reviewers definitely working with them, at least a few actually in the weeds. We’ll start with “time to exploitation has been reduced to minutes” which is almost certainly based on the recent “Zeroday Clock“, the associated press, and their claims. However, I recently pointed out that there is at least one serious issue with their methodology that would require refactoring any of their claims and assertions. So this claim from the authors of ‘Mythos Ready’ should have been vetted better and/or disclaimed heavily. Bad start in this paragraph.
Next, when I read “we can no longer assume a patch will be ready in time for remediation purposes” I have to ask how three authors, 16 co-authors, and 73 reviewers let this stand. Ignoring the fact that some co-authors are blowhard windbags with no real experience in vulnerabilities in the context at hand, I would love for any of them to stand up and tell me who thought they could assume patches would be ready in time before Anthropic came along, let alone their Glasswing / Mythos project. That is just absurd and a big red flag.

Readers of this blog can probably picture how much laughter erupted when I read “the CVE system may not scale” since it hasn’t scaled since its inception in 1999. I discussed this in two different ways years ago and recently in the feedback for the Zeroday Clock (search “1999” in each blog). Last year I gave the CVE program a “Vote of No Confidence” and also reminded readers of the Congressional investigation due to CVE being deficient in vulnerability coverage back in 2017 and before. This is another statement that baffles me given the authors and reviewers.
Finally, “threat intelligence is lagging behind on vulnerability discovery and exploitation” is a fun one to dissect. While not a formal “KEV” catalog, I had been tracking threat actors and campaigns using vulnerabilities for many years before CISA’s KEV came along. It was not a primary focus and I could not devote enough time toward it then, most of the vulnerability world was lagging more than I was. So this is another confusing statement when you put it together with the introduction: “This matters because many of the assumptions underlying our cyber defense programs are being challenged. For example .. threat intelligence is lagging behind on vulnerability discovery and exploitation.” So people are challenging that TI is lagging on vulnerability exploitation? Forgetting that TI generally is divorced from vulnerability discovery for many of us, one is a reaction to the other, if anyone thinks we have ever not lagged then I have some bad news for you.
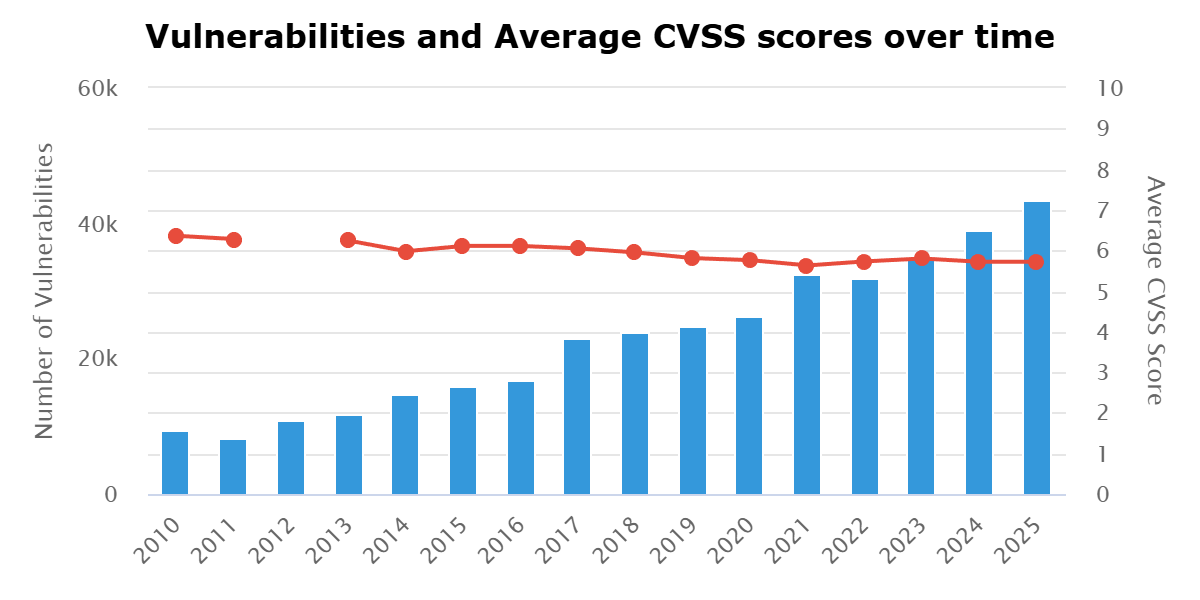
As of Monday, CISA’s KEV stands at 1,559 vulnerabilities, EUVD at 1,572, VulnCheck at 4,757, and VulnDB at 7,014. On January 1, 2025, VulnDB stood at 4,123. I can assure you that the almost 3,000 difference was not all newly exploited. That jump represents a concerted effort to catalog KEV, past or present. Since that number continues to grow, and again, not just from newly exploited vulnerabilities, it perfectly demonstrates that this intelligence has always been lagging. See the previously cited blogs on KEV thoughts above for some of the challenges and reasons for this.
Just that one paragraph has me deeply concerned about the veracity of these claims and fundamental (mis)understanding of the state of the vulnerability ecosystem. I know many of the listed contributors know about vulnerabilities to some degree or another, sure, but a vast majority of them do not work ‘in the weeds’, meaning analyzing the underlying vulnerability disclosures, aggregating them, and adding the valuable metadata. Most are ‘meta’ analysts of the vulnerability landscape at best and it shows. The list is so heavily weighted toward C-level positions and I don’t recognize a single person that has e.g. worked on a vulnerability database for even a year. Trust me, as someone who has been a VP and worked in the weeds, that context and perspective make all the difference in the world.
Or.. was The Cloud Security Alliance’s wording confusing and they mean the current state of affairs mentioned above is not working right now? Or perhaps all of these C-levels and blowhards are just too far out of the loop of the reality of the situation and drastically understating the reality? I hope so for their sake.
Pushback

Tom’s Hardware
Let’s start with public pushback already, beginning with a great article by Jon Martindale on Tom’s Hardware titled “Anthropic’s Claude Mythos isn’t a sentient super-hacker, it’s a sales pitch — claims of ‘thousands’ of severe zero-days rely on just 198 manual reviews“. That’s a pretty compelling headline. He breaks down a lot of great points from a 250-page report from Anthropic that goes into a lot more detail than prior information as well as the two blog posts linked earlier in the blog.
Martindale’s sub-heading goes on to say “Many of the “thousands” of bugs and vulnerabilities it found are in older software, or are impossible to exploit.” One example he cites is an out-of-bounds read issue in FFmpeg that Anthropic gloats about since “this weakness has been missed by every fuzzer and human who has reviewed the code, and points to the qualitative difference that advanced language models provide.” However, right above this is the more important takeaway, that while others missed it, this amazing new tool is good at finding difficult-to-exploit weaknesses just like humans:
This bug ultimately is not a critical severity vulnerability: it enables an attacker to write a few bytes of out-of-bounds data on the heap, and we believe it would be challenging to turn this vulnerability into a functioning exploit.
From there if you read on, you are hit with hyperbole and contradicting claims for many of the alleged vulnerabilities they found, with one promising capability discussed after. So let’s break down Anthropic’s new flagship offerings in Mythos’ capability of finding vulnerabilities! Note that instances of bold text are my own. Starting with OpenBSD we get a nothingburger and serious hyperbole, suggesting that a remote DoS of an OpenBSD web server can bring “down corporate networks“, implying the entire network rather than one server:
This is the first bug—but it is typically harmless, because acknowledging bytes -5 through 10 has the same effect as acknowledging bytes 1 through 10. In practice, denial of service attacks like this would allow remote attackers to repeatedly crash machines running a vulnerable service, potentially bringing down corporate networks or core internet services.
Next, we have unnamed Virtual Machine Monitor (VMM) software, due to the issue not being fixed. It also isn’t clear if it was not able to create an exploit for the denial of service, the exploit chain, or both. Stellar vulnerability disclosing just like humans:
It is easy to turn this into a denial-of-service attack on the host, and conceivably could be used as part of an exploit chain. However, Mythos Preview was not able to produce a functional exploit.
For the Linux Kernel, there is a mix of good and bad. We’ll start with the bad, where once again they are honest and deliver another nothingburger. When talking about issues in this context, it is important to remember the difference between a stability bug and a vulnerability. The first means there is no gain to an attacker, even if they can trigger it. The best example is if I can give you a PDF that crashes your reader. So what? You restart the reader, don’t load my PDF and move on. I have annoyed you no more than any other of the hundreds of benign stability bugs in that software. The latter means that the issue can cross privilege boundaries. In those cases, the attacker can trigger the bug and do something more than a trivial annoyance that benefits them, that was not intended. So when Mythos finds an issue, says it is triggerable, then says due to defense-in-depth (DiD) it could not actually exploit them? Not a vulnerability (NAV).
Many of these were remotely-triggerable. However, even after several thousand scans over the repository, because of the Linux kernel’s defense in depth measures Mythos Preview was unable to successfully exploit any of these.
Stepping back to look at the bigger picture of Mythos, we are fortunate that Anthropic is at least honest in parts of this document, dropping hyperbole while keeping contradicting statements. Even then we learn that their bold claims are based on some pretty flimsy extrapolation:
We have identified thousands of additional high- and critical-severity vulnerabilities that we are working on responsibly disclosing to open source maintainers and closed source vendors. While we are unable to state with certainty that these vulnerabilities are definitely high- or critical-severity, in practice we have found that our human validators overwhelmingly agree with the original severity assigned by the model: in 89% of the 198 manually reviewed vulnerability reports, our expert contractors agreed with Claude’s severity assessment exactly, and 98% of the assessments were within one severity level.
So they identified “thousands” of high or critical severity vulnerabilities, but they don’t actually know if they are high or critical, and they may be one severity level lower. This is not the flex you think it is Anthropic. A critical vulnerability (CVSS 9.0 -> 10.0) dropping to high (7.0 – 8.9) or that high dropping to medium (5.0 -> 6.9) are big drops in the world of vulnerabilities. They also don’t qualify what scoring system they are using for these claims. In fact, “CVSS” does not appear in any of the cited documents from Anthropic except once, where they cite someone else’s tool that found vulnerabilities. That should be a red flag to vulnerability practitioners as we know that the differences between CVSSv2, v3, and v4 can lead to wildly different scores. That CVSSv2 5.0 vulnerability can often be a CVSSv3 9.8 at the same time, a difference from medium to critical.
Where does Mythos shine, maybe? Finding some vulnerabilities in the Linux Kernel apparently, despite the above. Reading further into that section:
We have nearly a dozen examples of Mythos Preview successfully chaining together two, three, and sometimes four vulnerabilities in order to construct a functional exploit on the Linux kernel. For example, in one case, Mythos Preview used one vulnerability to bypass KASLR, used another vulnerability to read the contents of an important struct, used a third vulnerability to write to a previously-freed heap object, and then chained this with a heap spray that placed a struct exactly where the write would land, ultimately granting the user root permissions.
If this is true, that is impressive. Typically multi-vulnerability chains like this are/were the realm of high-end researchers and these chains often took weeks or even a month to figure out and write a reliable exploit for. In the past years these are also the domain of nation-state threat actors and we’re seeing more of them being discovered in the wild. Of course, with the previous section and the serious doubt Anthropic cast upon themselves specifically with Linux Kernel vulnerabilities we need to see real-world examples, plural, before we should truly find ourselves in awe.
The AI Security Institute
Next, we turn to The AI Security Institute, a research organisation within the Department of Science, Innovation and Technology out of the United Kingdom. On Monday, they published their evaluation titled “Our evaluation of Claude Mythos Preview’s cyber capabilities” which starts out by confirming what Anthropic said about multi-stage attacks, but in a different context. Rather than Linux Kernel local privilege escalation via two or more vulnerabilities, they used it to conduct multi-stage remote web-app based testing:
We have tracked AI cyber capabilities since 2023, building progressively harder evaluations to keep pace with AI progress — from chat-based probing, to capture-the-flag challenges, to the multi-step cyber-attack simulations described below. Two years ago, the best available models could barely complete beginner-level cyber tasks. Now, in controlled evaluations where Mythos Preview was explicitly directed and given network access to do so, we observed that it could execute multi-stage attacks on vulnerable networks and discover and exploit vulnerabilities autonomously – tasks that would take human professionals days of work.
The charts provided by the AI Security Institute showing the progression of testing are interesting as it compares different Large Language Models (LLM) over time and how well they did.

If I am interpreting this correctly, as of April 2026 they tested Mythos Preview and GPT 5.4 only so we don’t have a time-relevant baseline to compare the rest. However, note that while Mythos edged out GPT 5.4 in this time period, compare it to around September 2025 and you see GPT-5 placed higher than both, and that was half a year before in the “Technical non-expert” category. I won’t paste all of their charts, but the one following that also has a similar result where Mythos did well, but still not any better than GPT-5 in the “Practitioner” category.
Where their review gets interesting is once again in a mult-stage attack scenario. From their paper, edited slightly for brevity:
Real-world cyber-attacks require chaining dozens of steps together across multiple hosts and network segments — sustained operations that take human experts many hours, days, or weeks to complete. As a first step towards measuring this, we built “The Last Ones” (TLO): a 32-step corporate network attack simulation spanning initial reconnaissance through to full network takeover, which we estimate to require humans 20 hours to complete. [..] Claude Mythos Preview is the first model to solve TLO from start to finish, in 3 out of its 10 attempts. Across all its attempts, the model completed an average of 22 out of 32 steps. Claude Opus 4.6 is the next best performing model and completed an average of 16 steps.
Once again, Mythos shined on doing more complex chaining of vulnerabilities and outshined second place by a considerable margin. This is certainly more encouraging and interesting as this gives some promise to the model finding more complex vulnerabilities above the skill level of a majority of researchers currently disclosing vulnerabilities. On the other hand, over 40% of vulnerabilities disclosed last year fell into the category of web application vulnerabilities that are generally considered to be pretty easy to find. As with all vulnerabilities, some will be an exception but a vast majority can be found through tooling with little knowledge required by the tester. Here’s a breakdown of last year:
| 2025 Total Vulns | 45112 | 40.57% |
| XSS | 8231 | 18.2% |
| CSRF | 1841 | 4.1% |
| SQL Injection | 3760 | 8.3% |
| Path Traversal (Remote) | 1855 | 4.1% |
| Local File Inclusion | 661 | 1.5% |
| Command Execution (Remote) | 1249 | 2.87% |
| Server-Side Request Forgery (SSRF) | 556 | 1.2% |
| XML External Entity (XXE) Injection | 142 | 0.3% |
Disclaimers! 1) These are vulnerabilities as tracked by VulnDB, rather than counting CVE IDs which do not use consistent abstraction and are polluted by duplicate assignments. 2) Note that in previous years, SQL injection was often considered easy to find potential issues with the injection of a backtick, but much harder for many researchers to develop even a rudimentary proof-of-concept (PoC). However, with the widespread use of SQLmap it has become trivial in many cases not only to find a confirmed vulnerability, but have it generate a full working exploit. 3) Many local file inclusion issues reported are actually remote file disclosures, which is considerably different, yet amateur researchers frequently conflate the two. 4) Remote command execution is being included, because injecting e.g. ‘id’ is fairly trivial to find, where remote code execution can be considerably more complicated therefore not included. 5) There are other vulnerability classes such as Broken Access Controls that can be trivial to find, but were not included in my table because some require more in-depth knowledge potentially.
Nico Waisman
Finally, a colleague shared commentary on LinkedIn about Mythos by Nico Waisman that I wanted to briefly include, since they give commentary on Mythos:
Discovery is solved. Or close enough to solve that it’s no longer the bottleneck. The bottleneck is now: which findings actually matter?
I strongly disagree, because the biggest bottlenecks (plural) are right there in front of you for just over two years. Primarily the CVE and NVD bottlenecks, and they are continuing to be the bigger problem. When you look at all of this in the bigger picture, from discovery to disclosure to operationalizing the data, that is the vulnerability disclosure pipeline. Be it researchers or LLMs finding vulnerabilities, for a vast majority of organizations in the world if there are no CVE entries that are open with enriched data by NVD or CISA, then the data isn’t easily used.
Further, the growing number of disclosures over the past fifteen years show this is not a bottleneck, otherwise the rate would be stagnant at a certain point. Not that I put much faith in FIRST when it comes to the vulnerability landscape, but they are useful to prove a point here when they say “Realistic scenarios suggest 70,000 to 100,000 vulnerabilities are entirely possible this year“. That doesn’t sound like a bottleneck to me.
My Thoughts
So where do I land in all this? As always, “AI” isn’t actual artificial intelligence. As I constantly have to remind people, until it passes the Turing Test it just isn’t. These are LLMs, often serving a specific purpose (e.g. Mythos Preview) or broader models that attempt to be a friendly version of search engines (e.g. Gemini, ChatGPT) when they aren’t hallucinating. With that important disclaimer out of the way, talking about the Mythos tool specifically, then it seems like it is a great next evolution of vulnerability discovery tools in some contexts.
If further evidence demonstrates their claims, it is the next hot thing to come along and it will find a lot of vulnerabilities. Great! But first, let’s talk about what that really means and the fallout we may witness. As mentioned above, finding the vulnerability is the very first step in the entire process. Next, hopefully it is reporting the vulnerabilities to the vendor but there is no guarantee any vulnerabilities found by this tool will be, and no guarantee a fix will be created in a reasonable time, and no guarantee others don’t find the same vulnerability with the same tool but have more nefarious purposes. Most reading this likely won’t realize this because, as noted before, they simply don’t work in the weeds on vulnerabilities: just one of the partners listed (Microsoft) already is a bottleneck on disclosing vulnerabilities. The Microsoft Security Response Center (MSRC) is a pain point for many researchers trying to coordinate disclosure.
First, a little jab at Anthropic because they repeatedly use the term “responsible” disclosure, rather than “coordinated”, which is more accurate and fair to researchers. They too have fallen into the trap set by Microsoft all those years ago by Scott Culp and his absurd “Information Anarchy” whining. After that we saw Chris Betz of MSRC plead for better coordinated disclosure back in 2015, which too was problematic. The irony is thick since Microsoft is now a partner in all this and may not fully understand the box they opened for themselves is branded “Pandora“.

Using Microsoft as the example, and knowing the expertise and efficiency of MSRC varies greatly year to year, imagine trying to disclose three times the vulnerabilities to them. Now imagine five times, ten times, or fifty times the volume. They are already drowning as is and turnaround for acknowledging and fixing vulnerabilities can be dreadful for some (crappy treatment from vendors, long silences, no replies, arguing if a vulnerability, and more). This eventually leads to blowback as seen by the recent BlueHammer exploit that was published without coordination, due to frustration with MSRC.
That’s just one vendor and trust me, researchers are increasingly frustrated with more and more of the big vendors, as much as MITRE and some CVE Numbering Authorities (CNA). Can you imagine what an extra 50,000 vulnerabilities this year might mean when less than half are coordinated with the vendor? When less than half carry a CVE ID? You do realize that there are almost no vulnerability databases (VDB) that are broad-coverage and CVE agnostic? I can think of one and if you read this blog, you know exactly who I am talking about.
So that bottleneck that Waisman mentioned is again not the actual bottleneck in many cases, and Microsoft is just one vendor. Let’s imagine that Mythos and all of the other LLMs are all heavily adopted this year and that vulnerability disclosures double as a conservative estimate. How many will be issued a CVE? Remember that if you aren’t reported to a (CNA) then you report it to MITRE, which has its own troubles, bottlenecks, and contempt from many developers and researchers.
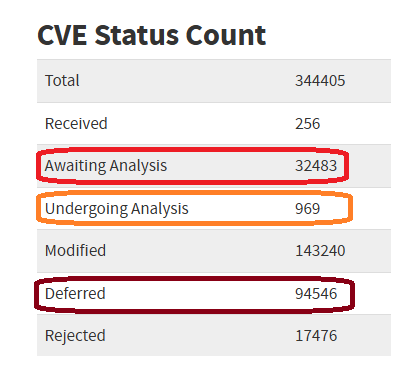
That means we can expect a significant percentage to be disclosed without a CVE ID, or perhaps with one but in RESERVED status. Next, it goes to NVD where the real bottleneck is. As of yesterday, over 32,000 vulnerabilities are awaiting analysis which means almost all of them do not have CVSS scores, and they do not have CPE which allows for programmatic consumption by tools. Basically, you can’t operationalize this data yet. There are almost another 1,000 that are undergoing analysis and not ready, and over 94,000 that NVD has deemed “we’re likely to never touch again”.
That’s the reality of the CVE ecosystem today. Now jump back to my thought exercise of three, five, ten, or fifty times the volume of vulnerabilities. Oh, did I forget to mention that all those discoveries will need to be validated by humans, either researchers, organizations, or vendors? That is what Mythos offers us more than anything, and that is the dark reality it brings. Yay vulnerabilities! But also a big cheer for threat actors as more vulnerabilities are available to them. We know for a fact that many of them frequently use publicly disclosed vulnerabilities and exploit code rather than spending time to discover their own. Organizations can’t keep up with patching under the current load of disclosures which doesn’t bode well for this year or after.
Ultimately, it doesn’t matter just how well Mythos finds vulnerabilities. If it even contributes to disclosures by a factor of 25%, it’s already going to be just as harmful to organizations as helpful. If it introduces a factor of 200% then you might as well begin Googling on how to start a goat sanctuary or learn basket weaving. Because you sure as hell won’t want to live the InfoSec life any longer.

Leave a Reply